img_size = mnist.train.images[0].shape[0]
1 | import numpy as np |
执行上述语句返回的结果为:
Label: 0
784
(784,)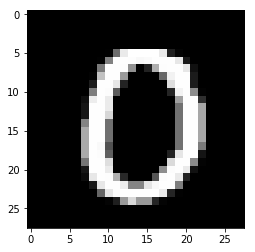
hidden1 = tf.layers.dense(noise_img, n_units)
1 | def get_generator(noise_img, n_units, out_dim, reuse=False, alpha=0.01): |
上述代码中的”hidden1 = tf.layers.dense(noise_img, n_units)“
其中:
noise_img-表示输入层的单元个数,这里使用了占位符表示,但要表明单元大小,个数为None
n_units-表示第一个隐藏层中神经元个数,
这里的函数,表示是全连接,将输入层的神经元全部与第一个隐藏层的神经元,进行全连接。


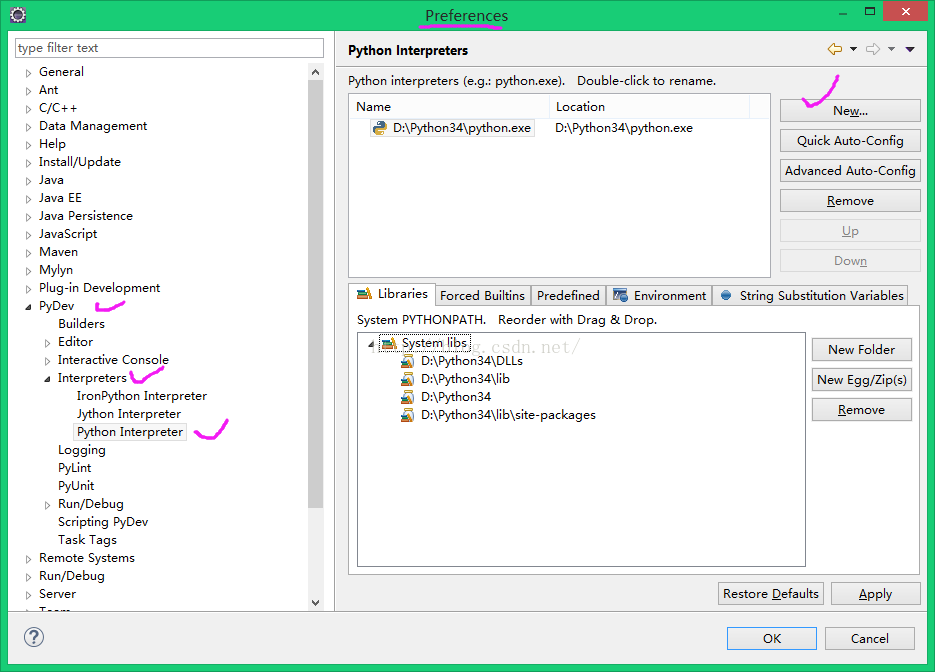
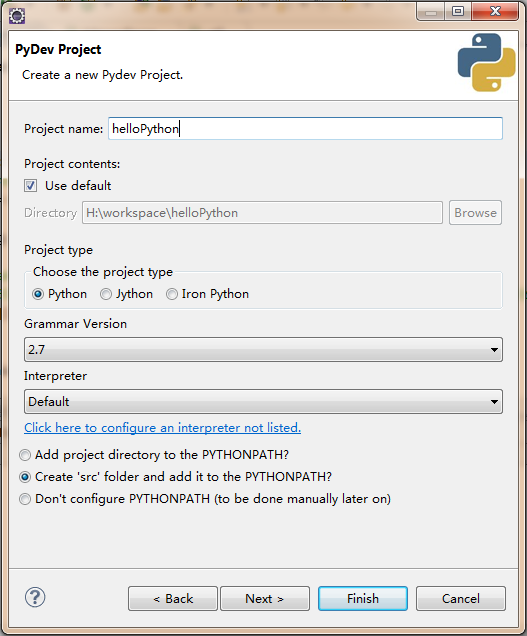
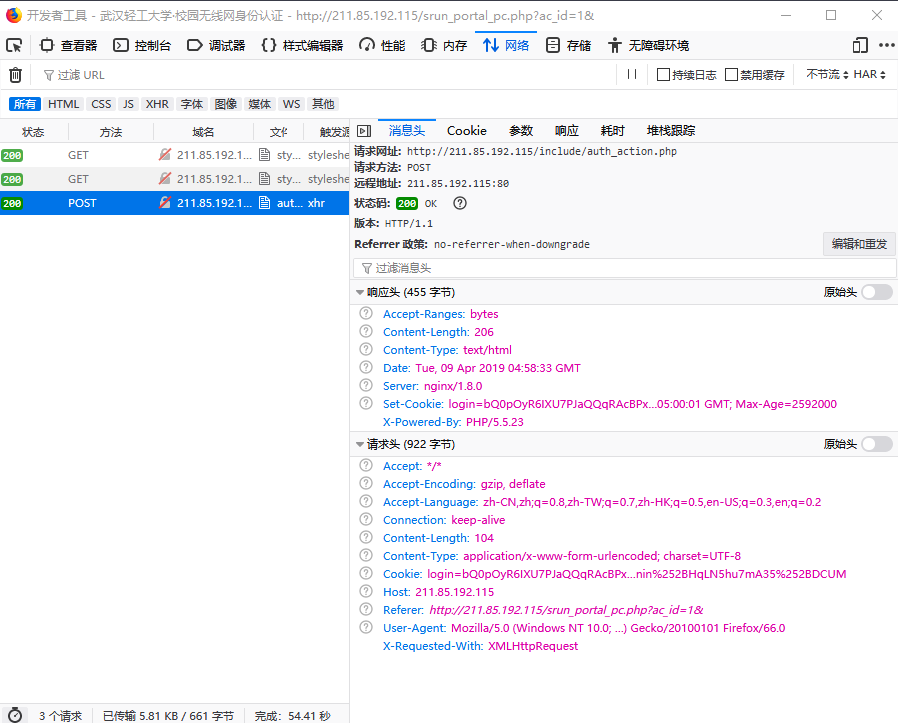
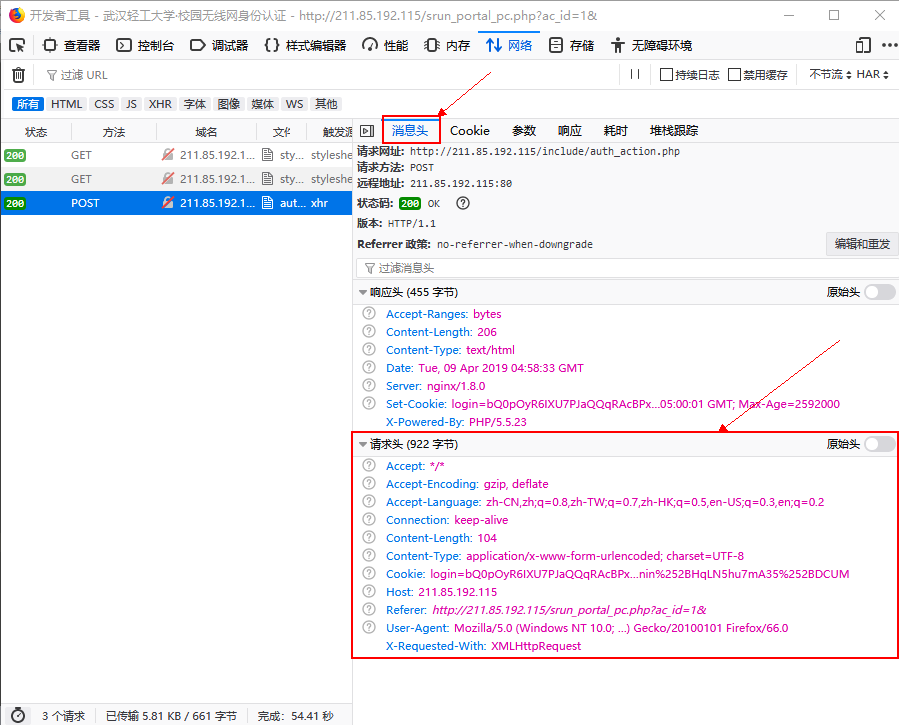
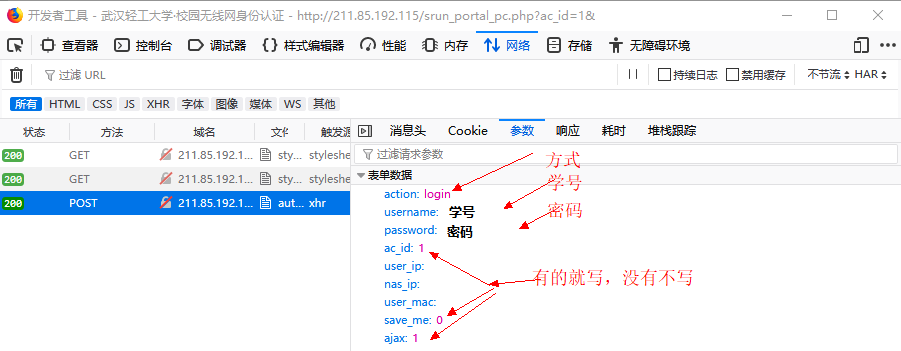

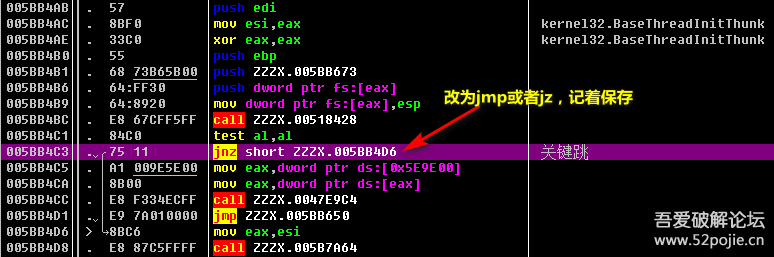
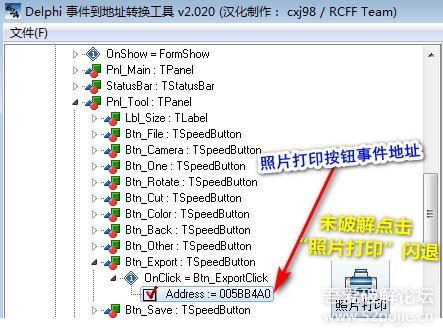

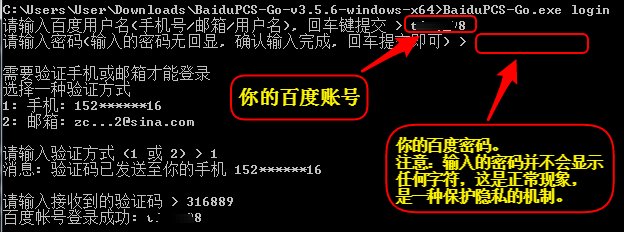
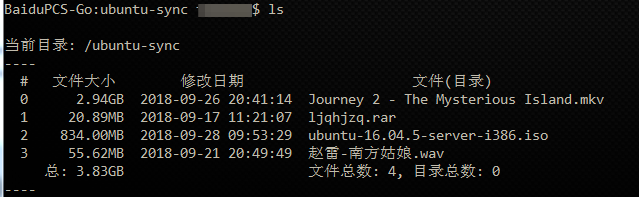
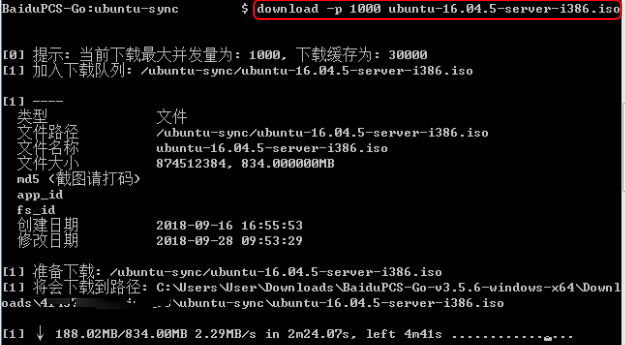
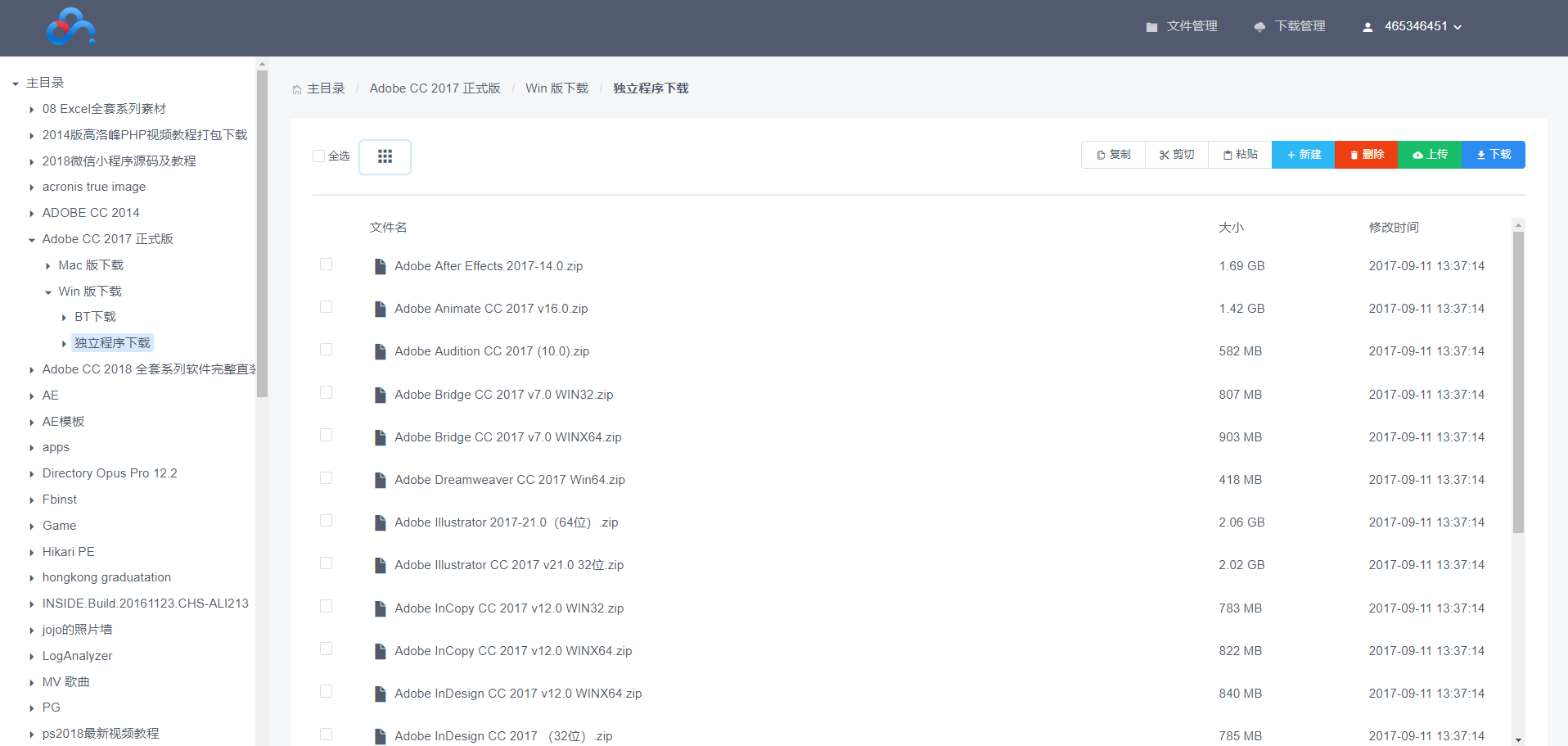

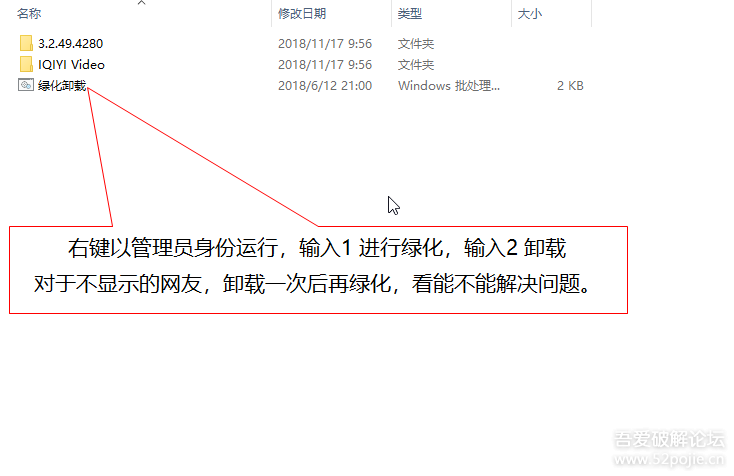
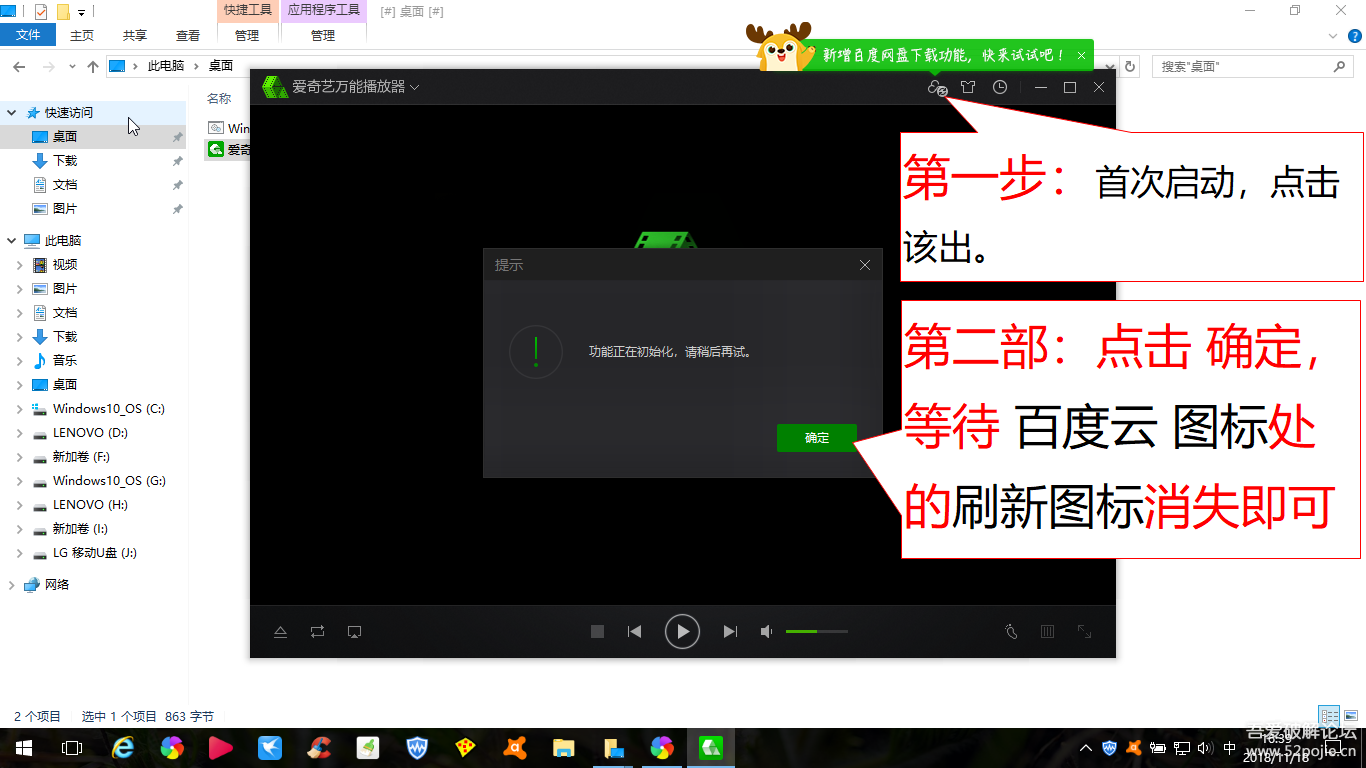
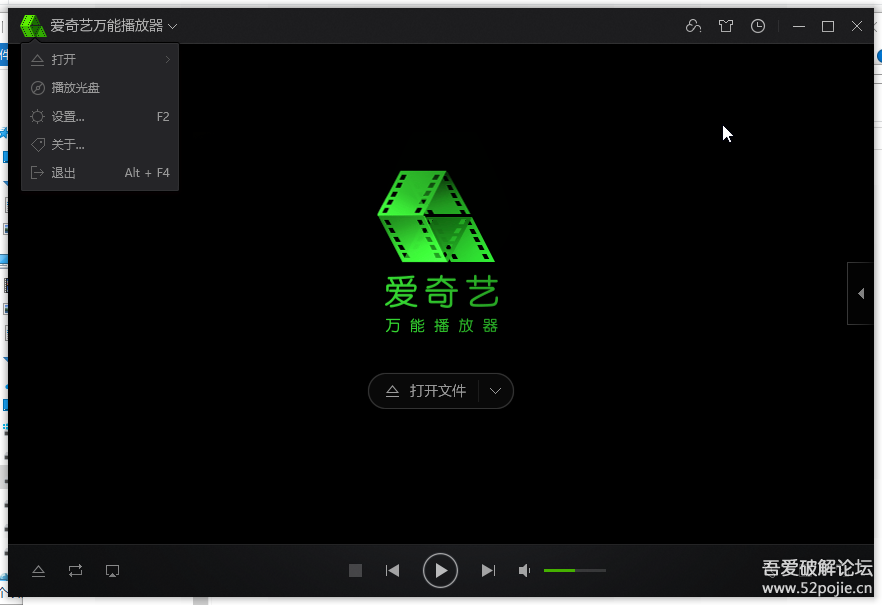
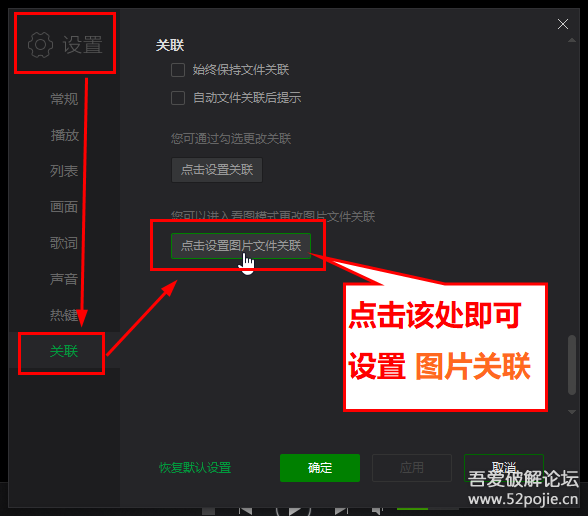
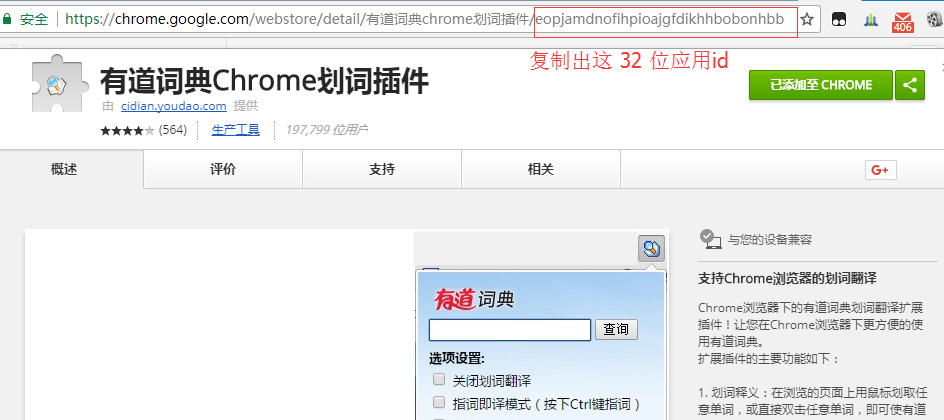
之后看不到请求头信息/img1-1.png)
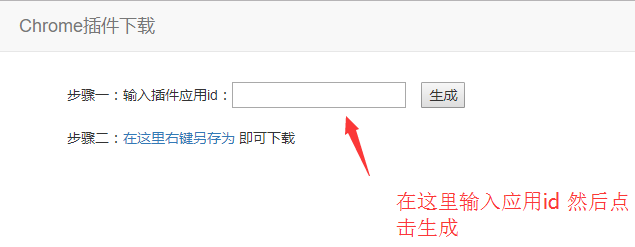
之后看不到请求头信息/img1-2.png)
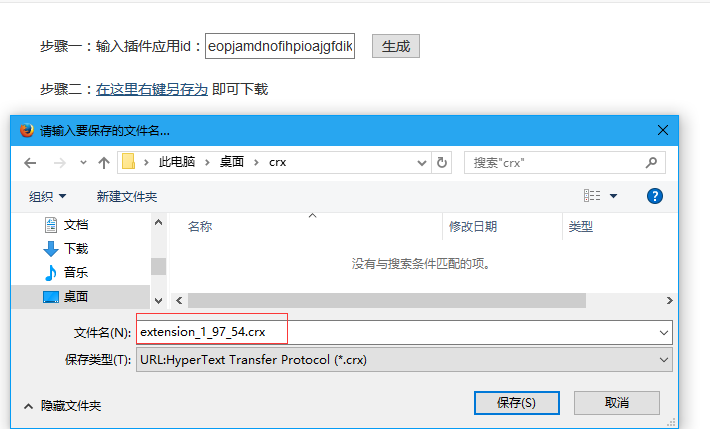
之后看不到请求头信息/img1-3.png)
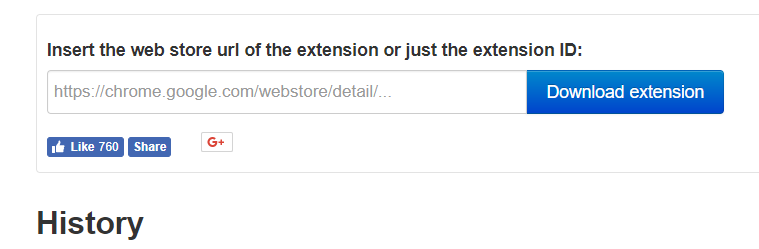
之后看不到请求头信息/img1-4.png)


/videoaddr.png)