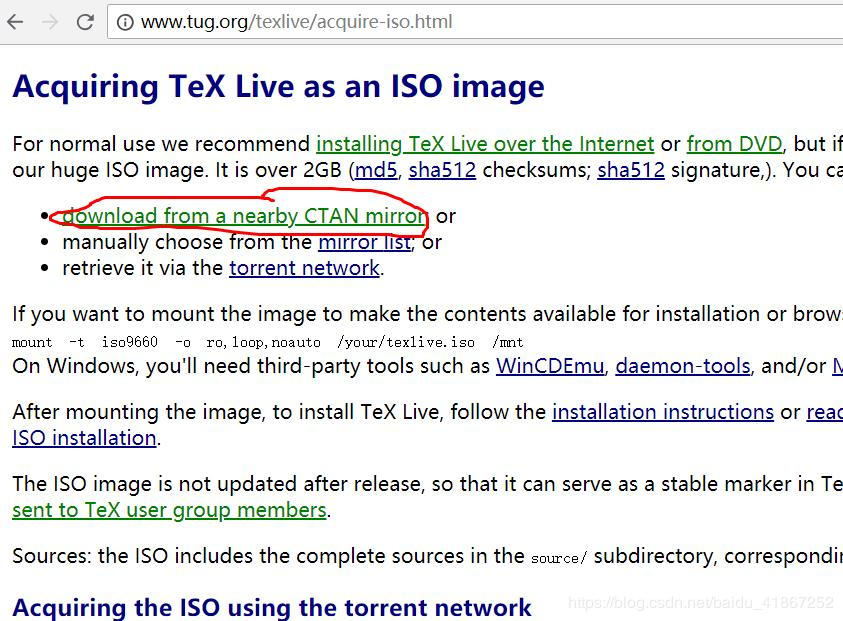
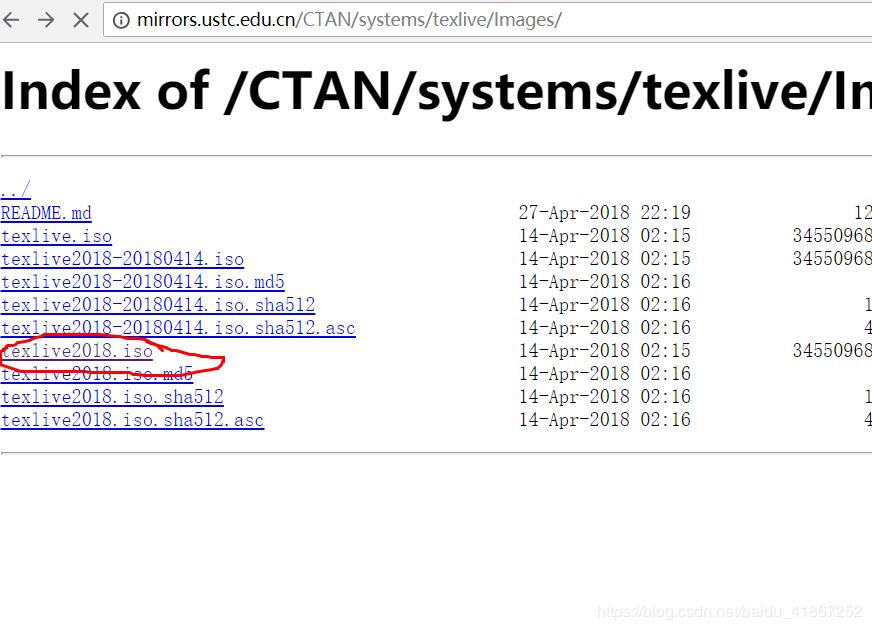
我觉得网上的一些资料大多是直接给出处理的结果,而不注重分析过程,对我们程序员来说,其过程更重要,工作中碰到的问题是多种多样的,不可能每个碰到的问题都能从网上直接找到答案,我也觉得作为程序员直接去找答案的做法本身有问题.应该提高主动去分析解决问题的能力.下面是对这类问题的一个相对通用的分析方法.
URL分析
http://v.qq.com/cover/g/g9jgclyhpp5sp7p.html?vid=g00118pmaso
打开这个url的页面源码,找到下面这些内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16var COVER_INFO = {
title :"独家首发",
id :"g9jgclyhpp5sp7p",
isPrev :false,
pic :"http://i.gtimg.cn/qqlive/img/jpgcache/files/qqvideo/g/g9jgclyhpp5sp7p_h.jpg",
typeid:22,
videoReName :false,
sourceid:0,
isEurope:false,
useTextVideoList:false,
columnid:0,
hasRecommend:true,
specialTemp:false,
varietyDate:"",
copyright:5
};
在源码中搜索g9jgclyhpp5sp7p字符串,从其出现的位置基本可以判断这个字符串唯一代表了一个合集(或者叫专辑). 不管它有没有用,先大概看一下,把URL中觉得有用的东西过一遍.
腾讯视频播放地址的url有几种模式,上面是其中一种,其它的几种模式对解析其地址没什么太大关系,这里就以这种为例了.这个url中最关键的就是最后面接的一个参数vid(videoID)=g00118pmaso.
抓包
这里首先要说一点,平时做web应用或者后台接口,要有习惯去抓包,并且对抓到的包进行一些简单的分析,这是一个很好的习惯,有时候会学到一些意想不到的东西.
最简单的抓包方式就是直接用浏览器自带的工具了,我平时用的chrome,F12 - Network中就有当前页面发送出去的http报文,另外还有个小技巧,因为浏览器会有缓存,按Ctrl+F5刷新页面,就会强制从服务端获取内容而不用缓存,有时候需要这样做,具体的原理可以去看看http协议中的Cache-Control头部. 用浏览器抓包还有个不太方便的地方,当页面跳转时,前面抓的包就没有了,抓的永远是当前页面相关的报文.所以我平时用的比较多的是fiddler,一个免费的抓包工具,非常方便.
回到正题, 我们从浏览器输入链接http://v.qq.com/cover/g/g9jgclyhpp5sp7p.html?vid=g00118pmaso, 抓到了很多http包,我这里给出一部分的截图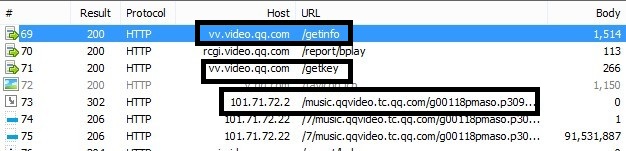
标出来的部分请求是关键请求, 我自己在分析的时候,是从下往上分析的,
1)首先找到视频的下载地址1
2
3
4
5http://101.71.72.2/music.qqvideo.tc.qq.com/g00118pmaso.p309.1.mp4?sdtfrom=v10&type=mp4
&vkey=95C006D54AA7217B859B15732EE04FB88B3986D36E53116ECAF1CFD43EE6615BA6AD5DDDF8CC3D7B
&level=3&platform=1&br=351&fmt=fhd&sp=0
这里继续分析url,g00118pmaso上面讲到了,是vid,但是后面多出了.p309.1. 继续往下看sdtfrom=v10(未知),type=mp4,这个好理解,vkey=95C006D54AA7217B859B15732EE04FB88B3986D36E53116ECAF1CFD43EE6615BA6AD5DDDF8CC3D7B,这个看起来又像是一个比较关键的参数,
- level=3(后面xml中对应的level),
- platform=1(平台,web、client、iphone…?暂时也是未知),
- br=351(bitrate=351?大概是码率的意思,后面xml中的br=351),
- fmt=fhd(大概意思是format=flvHD?实际上这里是后面id为10309对应的format name),
- sp=0(后面xml中对应的sp).
这里有一大堆的参数,有很多都是未知,这个时候别慌,整个链接直接下载肯定是可以下载到视频的,现在要做的是,去掉其中一些参数,看是否能下载.1
http://101.71.72.2/music.qqvideo.tc.qq.com/g00118pmaso.p309.1.mp4?type=mp4&vkey=95C006D54AA7217B859B15732EE04FB88B3986D36E53116ECAF1CFD43EE6615BA6AD5DDDF8CC3D7B&br=351&fmt=fhd
最后发现,保留这些参数,能正常下载到视频。所以其它参数暂时先别管。这里有几个关键的地方,vkey从哪里来的?br和fmt从那里获取?vid后面的p309.1哪里来的?还有就是ip地址来源未知。分析到这里,继续往上找到另一个比较关键的请求。
分析玩上面的视频地址链接的组成,很容易就找到了这个请求,getkey。它是一个post请求,查看其发送的参数format=10309&otype=xml&vt=210&vid=g00118pmaso&ran=0%2E9477521511726081&charge=0&filename=g00118pmaso%2Ep309%2E1%2Emp4&platform=11
http response中的内容如下:1
2
<root><br>360602.1875</br><ct>604800</ct><key>95C006D54AA7217B859B15732EE04FB88B3986D36E53116ECAF1CFD43EE6615BA6AD5DDDF8CC3D7B</key><level>3</level><levelvalid>1</levelvalid><s>o</s><sp>0</sp><sr>0</sr></root>
在这里我们找到了key,同时还发现了和上面链接对应的level和sp两个参数,上面一个链接中的一个参数,不过这个参数也非必要,暂时不管。1
2
3
4
5URLDecode后为:
format=10309(这里实际上是后面的format id)&otype=xml&vt=210&vid=g00118pmaso
&ran=0.9477521511726081&charge=0&filename=g00118pmaso.p309.1.mp4&platform=11
同样,在代码中试,看那几个参数是必要的,经试验,发现format,type,vid,filename是必要的。
继续网上分析第三个url,http://vv.video.qq.com/getinfo
也是一个POST请求,参数是:1
2otype=xml&pid=2FAF2F6427123207101EBDA3F1523310A76216BD&
platform=11&vids=g00118pmaso&charge=0&speed=1246&ran=0.8439321480691433
返回的结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
<root>
<fl>
<cnt>5</cnt>
<fi>
<br>64</br>
<id>1</id>
<name>flv</name>
<sl>0</sl>
</fi>
<fi>
<br>550</br>
<id>10301</id>
<name>shd</name>
<sl>0</sl>
</fi>
<fi>
<br>230</br>
<id>10302</id>
<name>hd</name>
<sl>0</sl>
</fi>
<fi>
<br>64</br>
<id>10303</id>
<name>sd</name>
<sl>0</sl>
</fi>
<fi>
<br>900</br>
<id>10309</id>
<name>fhd</name>
<sl>1</sl>
</fi>
</fl>
<hs>0</hs>
<ls>0</ls>
<preview>276</preview>
<s>o</s>
<tm>1361366724</tm>
<vl>
<cnt>1</cnt>
<vi>
<br>351</br>
<ch>0</ch>
<cl>
<ci>
<cd>276.480011</cd>
<cmd5>beace783957b52f460006604229b57cf</cmd5>
<cs>99699295</cs>
<idx>1</idx>
<keyid>g00118pmaso.10309.1</keyid>
</ci>
<fc>1</fc>
</cl>
<fmd5>4ebecd94d64f46666d4e43826c120b5f</fmd5>
<fn>g00118pmaso.p309.mp4</fn>
<fs>99699378</fs>
<fst>5</fst>
<lnk>g00118pmaso</lnk>
<logo>1</logo>
<pl>
<cnt>2</cnt>
<pd>
<c>10</c>
<cd>2</cd>
<fmt>40001</fmt>
<fn>q1</fn>
<h>45</h>
<r>10</r>
<url>http://video.qpic.cn/video_caps/0/</url>
<w>80</w>
</pd>
<pd>
<c>5</c>
<cd>2</cd>
<fmt>40002</fmt>
<fn>q2</fn>
<h>90</h>
<r>5</r>
<url>http://video.qpic.cn/video_caps/0/</url>
<w>160</w>
</pd>
</pl>
<share>1</share>
<st>2</st>
<td>276.48</td>
<ti>因你而在</ti>
<type>3585</type>
<ul>
<ui>
<dt>2</dt>
<dtc>10</dtc>
<url>http://101.71.72.2/music.qqvideo.tc.qq.com/</url>
<vt>210</vt>
</ui>
<ui>
<dt>2</dt>
<dtc>10</dtc>
<url>http://113.207.98.27/music.qqvideo.tc.qq.com/</url>
<vt>210</vt>
</ui>
<ui>
<dt>2</dt>
<dtc>10</dtc>
<url>http://video.store.qq.com/</url>
<vt>0</vt>
</ui>
</ul>
<vh>1080</vh>
<vid>g00118pmaso</vid>
<videotype>0</videotype>
<vw>1920</vw>
</vi>
</vl>
</root>
看到这个后,比较兴奋,想要的东西基本上在这里可以找到了。再回过来分析一下这个请求所带的参数1
2
3otype=xml&pid=2FAF2F6427123207101EBDA3F1523310A76216BD
&platform=11&vids=g00118pmaso&charge=0&speed=1246&ran=0.8439321480691433
- otype返回格式,
- pid看起来又像是个比较重要的参数(未知),
- platform(上面是1,这里又来了个11,不明白),
- vid和上面一样,charge(应该是付费信息,0表示不付费,来源未知),speed(未知),ran和上面一样应该是个0-1之间的随机数。
用httpclient模仿这个请求,令人兴奋的是只需要vids和otype就能返回该xml(不需要再去找pid了)。
再整理一下:
1.先通过http://vv.video.qq.com/getinfo POST请求添加参数otype,vid就能获得上面的xml。
2.根据这个xml中的内容发送http://vv.video.qq.com/getkey POST请求,参数列表为format,type,vid,filename。
其中format的id和name有个对应关系,10309-fhd、10303-sd、10302-hd。这里填写的为id。例如:format=10309
filename由几部分组成g00118pmaso.p309.1.mp4 最前面一部分是vid,如果格式id为10309,则后面加上p309.1,最后是格式mp4。例如我我要下载格式id为10303的视频,那拼出来应该是g00118pmaso.p303.1.mp4。
type为xml,vid为每个视频唯一的id,这里是g00118pmaso。
3.根据以上信息拼接视频的真实地址
首先是xml中的地址http://101.71.72.2/music.qqvideo.tc.qq.com
紧跟着拼上filename,这里例如g00118pmaso.p309.1.mp4、g00118pmaso.p303.1.mp4、g00118pmaso.p302.1.mp4、g00118pmaso.p301.1.mp4。注意filename要和vkey一一对应,不能用p309的key和g00118pmaso.p303.1.mp4拼接。
然后就是vkey,根据filename获得的vkey进行拼接。
接着type=mp4,fmt和format id对应,例如10309对应的是fhd。
对于format id为10309的视频,最后拼出来的结果是1
http://101.71.72.2/music.qqvideo.tc.qq.com/g00118pmaso.p309.1.mp4?type=mp4&vkey=95C006D54AA7217B859B15732EE04FB88B3986D36E53116ECAF1CFD43EE6615BA6AD5DDDF8CC3D7B&fmt=fhd
注意这里把一些不必要的参数去掉了。
4.若通过抓包的方式无法分析出来真实地址,则需要反编译swf,找到拼接视频地址的代码,还原其过程。
腾讯的视频地址分析还算顺利,因为不需要反编译swf